抄袭/参考资料
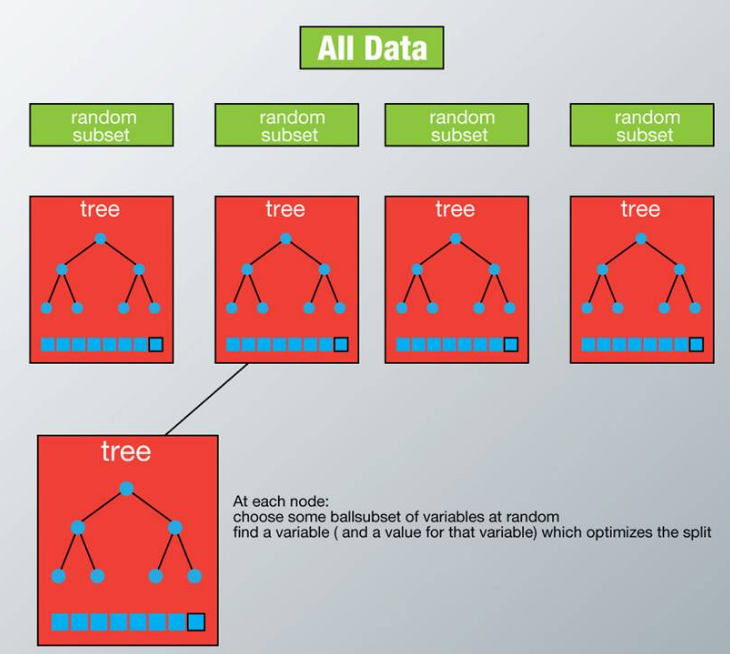
在随机森林中,我们将生成很多的决策树CART。当在基于某些属性对一个新的对象进行分类判别时,随机森林中的每一棵树都会给出自己的分类选择,并由此进行“投票”,森林整体的输出结果将会是票数最多的分类选项;而在回归问题中,随机森林的输出将会是所有决策树输出的平均值。
在随机森林中,每一个决策树“种植”(双随机)和“生长”的规则如下所示:
- 假设我们设定训练集中的样本个数为N,然后通过有重置的重复多次抽样(Bootstrap)来获得这N个样本,这样的抽样结果将作为我们生成决策树的训练集;
- 如果有M个输入变量,每个节点都将随机选择m(m<M)个特定的变量,然后运用这m个变量来确定最佳的分裂点。在决策树的生成过程中,m的值是保持不变的;
- 每棵决策树都最大可能地进行生长而不进行剪枝;
- 通过对所有的决策树进行加总来预测新的数据(在分类时采用多数投票,在回归时采用平均)。
优点
- 正如上文所述,随机森林算法能解决分类与回归两种类型的问题,并在这两个方面都有相当好的估计表现;
- 随机森林对于高维数据集的处理能力令人兴奋,它可以处理成千上万的输入变量,并确定最重要的变量,因此被认为是一个不错的降维方法。此外,该模型能够输出变量的重要性程度,这是一个非常便利的功能;
- 在对缺失数据进行估计时,随机森林是一个十分有效的方法。就算存在大量的数据缺失,随机森林也能较好地保持精确性;
- 当存在分类不平衡的情况时,随机森林能够提供平衡数据集误差的有效方法;
- 模型的上述性能可以被扩展运用到未标记的数据集中,用于引导无监督聚类、数据透视和异常检测;
- 随机森林算法中包含了对输入数据的重复自抽样过程,即所谓的bootstrap抽样。这样一来,数据集中大约三分之一将没有用于模型的训练而是用于测试,这样的数据被称为out of bag samples,通过这些样本估计的误差被称为out of bag error。研究表明,这种out of bag方法的与测试集规模同训练集一致的估计方法有着相同的精确程度,因此在随机森林中我们无需再对测试集进行另外的设置。
缺点
- 随机森林在解决回归问题时并没有像它在分类中表现的那么好,这是因为它并不能给出一个连续型的输出。当进行回归时,随机森林不能够作出超越训练集数据范围的预测,这可能导致在对某些还有特定噪声的数据进行建模时出现过度拟合。
- 对于许多统计建模者来说,随机森林给人的感觉像是一个黑盒子——你几乎无法控制模型内部的运行,只能在不同的参数和随机种子之间进行尝试。