抄袭/参考资料
- 台湾大学《机器学习技法》视频
- 使用sklearn进行集成学习——理论
- 机器学习-组合算法总结
- 深入浅出ML之Boosting家族
| 集成框架 | 特点 | 优点 | 实现 |
|---|---|---|---|
| Bagging | Bootstraping、均等投票 | 组合强模型,降低方差,防止过拟合 | 随机森林(改进的Bagging) |
| Boosting | “知错就改”、linear组合(有权重) | 组合弱模型,降低偏差,提高准确度 | Adaboost、Gradient Tree Boosting/GBRT |
| Stacking | 组合不同模型 | 组合强模型 | - |
偏差与方差
在统计学中,一个模型好坏,是根据偏差和方差来衡量的,所以我们先来普及一下偏差(bias)和方差(variance):
- 偏差:描述的是预测值(估计值)的期望$E’$与真实值$Y$之间的差距。偏差越大,越偏离真实数据
$$
Bias [\hat{f}(x)] = E [\hat{f}(x)] - f(x)
$$
- 方差:描述的是预测值$P$的变化范围,离散程度,是预测值的方差,也就是离其期望值$E$的距离。方差越大,数据的分布越分散。
$$
Var [\hat{f}(x)] = E [(\hat{f}(x) - E[\hat{f}(x)])^2]
$$
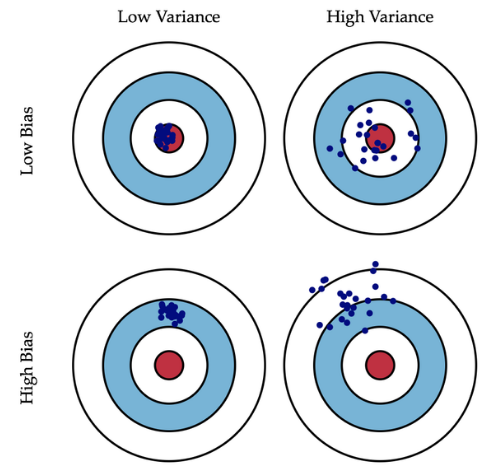
说直白点,模型的偏差和方差来描述其在训练集上的准确度和防止过拟合的能力
- 高方差:过拟合
- 高偏差:预测不精准
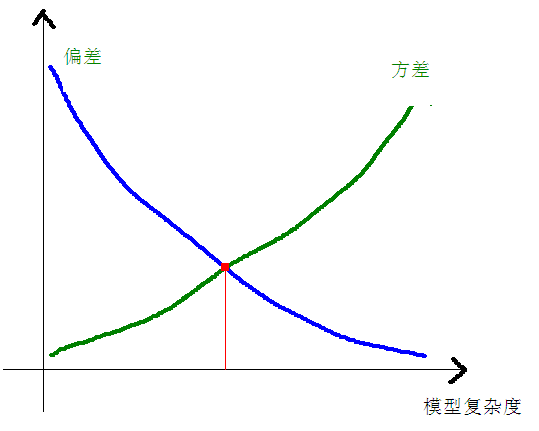
- 弱模型(低复杂度):高偏差&低方差
强模型(高复杂度):低偏差&高方差
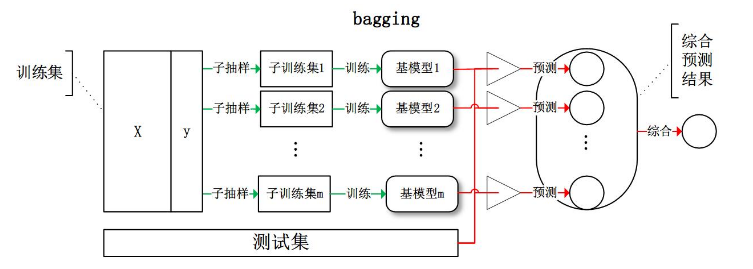
Bagging
Bootstraping
在了解Bagging之前,需先了解Bootstraping,称为自助法,它是一种有放回的抽样方法
Bagging其实是bootstrap appregating的缩写,依靠bootstrap抽取多个数据集,训练出多个不同模型,再有这些模型进行投票
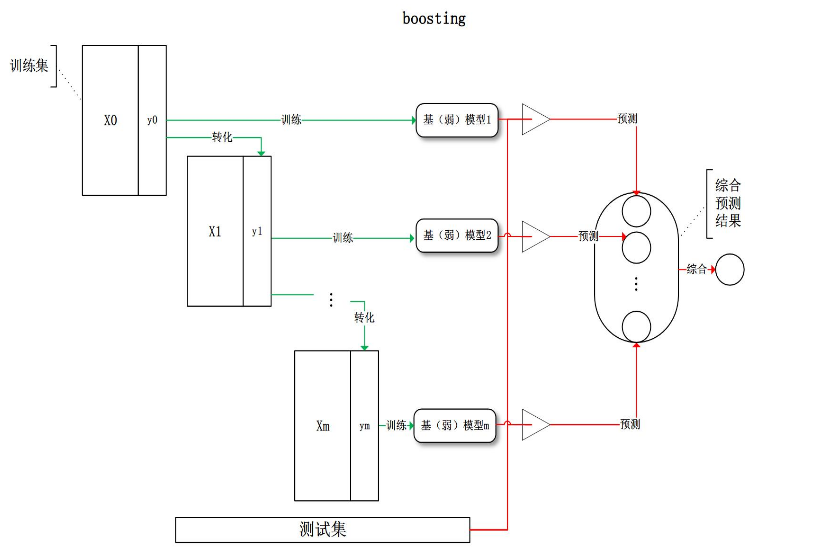
Boosting/提升
给定训练数据集,求一个弱学习算法要比求一个强学习算法要容易的多。Boosting方法就是从弱学习算法出发,反复学习,得到一系列弱分类器,然后组合弱分类器,得到一个强分类器。Boosting方法在学习过程中通过改变训练数据的权值分布,针对不同的数据分布调用弱学习算法得到一系列弱分类器。
具体不同的boosting实现,主要区别在弱学习算法本身和下面两个问题的回答上。
- 在每一轮学习之前,如何改变训练数据的权值分布?
- 如何将一组弱分类器组合成一个强分类器?
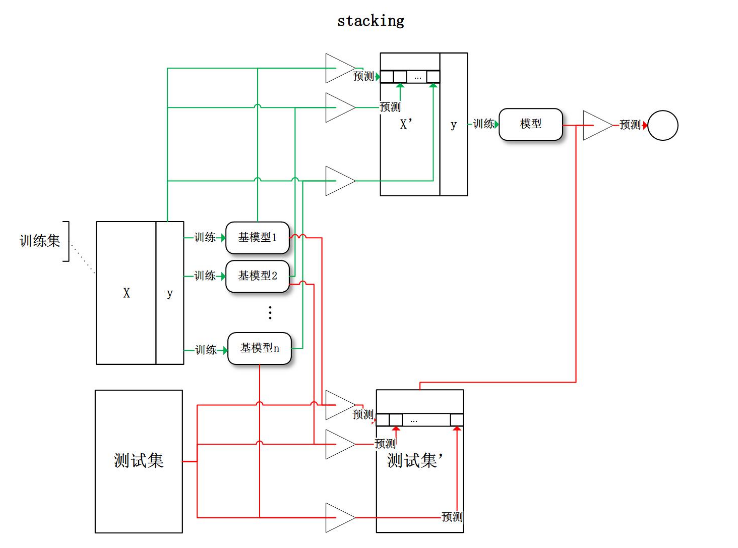
Stacking
将训练好的所有基模型对训练基进行预测,第j个基模型对第i个训练样本的预测值将作为新的训练集中第i个样本的第j个特征值,最后基于新的训练集进行训练。同理,预测的过程也要先经过所有基模型的预测形成新的测试集,最后再对测试集进行预测: