抄袭/参考资料
- 台湾大学《机器学习技法》视频
- 周志华《机器学习》
- 李航《统计学习方法》
- 决策树算法原理(上)
- 深入浅出ML之Tree-Based家族
决策树学习三步骤:
- 特征选择
- 决策树的生成
- 决策树的剪枝
常用的决策树算法有ID3,C4.5和CART。它们都是采用贪心(即非回溯的)方法,自顶向下递归的分治方法构造。这几个算法选择属性划分的方法各不相同,ID3使用的是信息增益,C4.5使用的是信息增益率,而CART使用的是Gini基尼指数。下面来简单介绍下决策树的理论知识。内容包含熵、信息增益、信息增益率以及Gini指数的概念及公式。
| 决策树算法 | 特征选择方法 |
|---|---|
| ID3 | 信息增益 |
| C4.5 | 信息增益比/增益率 |
| CART决策树 | 分类树:基尼值;回归树:最小二程 |
信息熵
熵度量了事物的不确定性,被用来衡量一个随机变量出现的期望值。熵越大,一个变量的不确定性就越大(也就是可取的值很多),把它搞清楚所需要的信息量也就越大,熵是整个系统的平均消息量。
信息熵是信息论中用于度量信息量的一个概念。一个系统越是有序,信息熵就越低;反之,一个系统越是混乱,信息熵就越高。所以,信息熵也可以说是系统有序化程度的一个度量。
设$X$是一个取有限个值的离散随机变量,其概率分布为:
$$
P(X=x_i)=p_i\\i=1,2,…n
$$
则随机变量$X$的熵定义为:
$$
Entropy=H(D)=E(I(D))=-\sum_{i=1}^{n} p_ilog_2(p_i),p_i是D中任意元组属于类C_i非零概率
$$
结论:熵越大,说明系统越混乱,携带的信息就越少(为了确定$X$我们需要更多的信息)。熵越小,说明系统越有序,携带的信息就越多(更容易确定$X$)。
举例:当随机变量只取两个值,例如0,1时,参考《统计学习方法》P60
互信息=信息增益
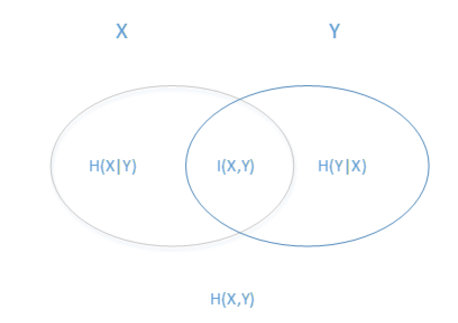
熟悉了一个变量X的熵,很容易推广到多个个变量的联合熵,这里给出两个变量X和Y的联合熵表达式:
$$
H(X,Y) = -\sum_{i=1}^{n}p(x_i,y_i)\log_2p(x_i,y_i)
$$
有了联合熵,又可以得到条件熵的表达式H(X|Y),条件熵类似于条件概率,它度量了我们的X在知道Y以后剩下的不确定性。表达式如下:
$$
H(X|Y) = -\sum_{i=1}^{n}p(x_i,y_i)\log_2p(x_i|y_i) = \sum_{j=1}^{n}p(y_j)H(X|Y=y_j)
$$
问题来了:
- $H(X)$度量了$X$的不确定性
- 条件熵$H(X|Y)$度量了我们在知道$Y$以后$X$剩下的不确定性
- 那么$H(X)-H(X|Y)$呢?
答案就是互信息【互信息=熵-条件熵】:它度量了$X$在知道$Y$以后不确定性减少程度!同时我们也可以把它记为$I(X,Y)$,称为信息增益。
说直白点,$I(X,Y)$ 缩小了需要确定的X的范围,$Y$帮助了$X$ 的程度 ,减少了信息熵!
ID3算法
ID3算法就是用信息增益大小来判断当前节点应该用什么特征来构建决策树,用计算出的信息增益最大的特征来建立决策树的当前节点。
https://github.com/stream886/machinelearninginaction
ID3的不足
ID3没有考虑连续特征,比如长度,密度都是连续值,无法在ID3运用。这大大限制了ID3的用途。
ID3偏好选择取值多的特征做分支,ID3采用信息增益大的特征优先建立决策树的节点。很快就被人发现,在相同条件下,取值比较多的特征比取值少的特征信息增益大。比如一个变量有2个值,各为1/2,另一个变量为3个值,各为1/3,其实他们都是完全不确定的变量,但是取3个值的比取2个值的信息增益大。
直白解释:取值比较多的特征,就可以分叉出更多的分支,分支更多,每个分支的纯度必然更高!ID3算法对于缺失值的情况没有做考虑
没有考虑过拟合的问题,即没有剪枝处理
信息增益率
它信息增益和特征熵的比值
$$
I_R(D,A) = \frac{I(A,D)}{H_A(D)}
$$
其中$D$为样本特征输出的集合,$A$为样本特征,对于特征熵$H_A(D)$, 表达式如下:
$$
H_A(D) = -\sum\limits_{i=1}^{n}\frac{|D_i|}{|D|}log_2\frac{|D_i|}{|D|}
$$
其中$n$为特征$A$的类别数, $D_i$为特征$A$的第$i$个取值对应的样本个数。$D$为样本个数。特征数越多的特征对应的特征熵越大,它作为分母,可以校正信息增益容易偏向于取值较多的特征的问题。
C4.5算法
C4.5与ID3算法为同一作者,C4.5是ID3的改进,其建书思路基本一致,主要是改进是ID3的四点不足之处。
- 对与 ID3没有考虑连续特征
C4.5的思路是将连续的特征离散化。比如$m$个样本的连续特征$A$有$m$个,从小到大排列为$a_1,a_2,…,a_m$,则C4.5取相邻两样本值的中位数,一共取得$m-1$个划分点,其中第$i$个划分点$T_i$表示为:$T_i = \frac{a_i+a_{i+1}}{2}$。对于这$m-1$个点,分别计算以该点作为二元分类点时的信息增益。选择信息增益最大的点作为该连续特征的二元离散分类点。比如取到的增益最大的点$a_t$,则小于$a_t$的值为类别1,大于$a_t$的值为类别2,这样我们就做到了连续特征的离散化。要注意的是,与离散属性不同的是,如果当前节点为连续属性,则该属性后面还可以参与子节点的产生选择过程。
- 对与 ID3偏好选择取值多的特征做分支
改用信息增益率作为分支指标,因为特征数越多的特征对应的特征熵越大,它作为分母,可以校正信息增益容易偏向于取值较多的特征的问题。
- 对与ID3算法对于缺失值的情况没有做考虑
主要需要解决的是两个问题,一是在样本某些特征缺失的情况下选择划分的属性,二是选定了划分属性,对于在该属性上缺失特征的样本的处理。
对于第一个子问题,对于某一个有缺失特征值的特征A。C4.5的思路是将数据分成两部分,对每个样本设置一个权重(初始可以都为1),然后划分数据,一部分是有特征值A的数据D1,另一部分是没有特征A的数据D2. 然后对于没有缺失特征A的数据集D1来和对应的A特征的各个特征值一起计算加权重后的信息增益比,最后乘上一个系数,这个系数是无特征A缺失的样本加权后所占加权总样本的比例。
对于第二个子问题,可以将缺失特征的样本同时划分入所有的子节点,不过将该样本的权重按各个子节点样本的数量比例来分配。比如缺失特征A的样本a之前权重为1,特征A有3个特征值A1,A2,A3。 3个特征值对应的无缺失A特征的样本个数为2,3,4.则a同时划分入A1,A2,A3。对应权重调节为2/9,3/9, 4/9。
- 对与**没有考虑过拟合的问题
C4.5引入了正则化系数进行初步的剪枝。
C4.5的不足
- 由于决策树算法非常容易过拟合,因此对于生成的决策树必须要进行剪枝。剪枝的算法有非常多,C4.5的剪枝方法有优化的空间。思路主要是两种,一种是预剪枝,即在生成决策树的时候就决定是否剪枝。另一个是后剪枝,即先生成决策树,再通过交叉验证来剪枝。
- C4.5生成的是多叉树,即一个父节点可以有多个节点,效率低(二叉数效率才高)。
- C4.5只能用于分类。
- C4.5由于使用了熵模型,里面有大量的耗时的对数运算,如果是连续值还有大量的排序运算。